Your programs should read files that are in the ARFF format. In this format, each instance is described on a single line. The feature values are separated by commas, and the last value on each line is the class label (for classification) or numeric response (for regression) of the instance. Each ARFF file starts with a header section describing the features, class labels, and numeric responses. Lines starting with '%' are comments. See the link above for a brief, but more detailed description of the ARFF format. Your program should handle numeric and nominal attributes, and simple ARFF files (i.e. don't worry about sparse ARFF files and instance weights). Example ARFF files are provided below.
Your programs should should implement a k-nearest neighbor learner according to the following guidelines:
kNN and should accept three
command-line arguments as follows:kNN
<train-set-file> <test-set-file> k
The second program should be named kNN-select and should
accept five command-line arguments as follows:
kNN-select
<train-set-file> <test-set-file> k1 k2 k3
This program should use leave-one-out cross validation with just the training data to
select the value
of k to use for the test set by evaluating k1 k2 k3
and selecting the one that
results in the minimal cross-validated error within the training set. To measure error for regression tasks,
you should
use mean
absolute error.
If you are using
a language that is not compiled to machine code (e.g. Java), then you
should make scripts called kNN and kNN-select that accept the
command-line arguments and invokes the appropriate source-code program
and interpreter. See HW #1 for instructions on how to make such a script.
As output, your programs should print the value of k used for the test set on the first line, and then the predictions for the test-set instances. For each instance in the test set, your program should print one line of output with spaces separating the fields. For a classification task, each output line should list the predicted class label, and actual class label. This should be followed by a line listing the number of correctly classified test instances, and the total number of instances in the test set. For a regression task, each output line should list the predicted response, and the actual response value. This should be followed by a line listing the mean absolute error for the test instances, and the total number of instances in the test set.
You should test your code on the following two data sets:
Here are the outputs your first program (kNN) should produce (where k is specified as an argument):
kNN-select program should produce when run
with k1=3, k2=5,
k3=7:
The first data set is for a task that involves predicting wine scores from chemical properties. The second data set is for a task that involves predicting the compartment in a cell that a yeast protein will localize to based on properties of its sequence.
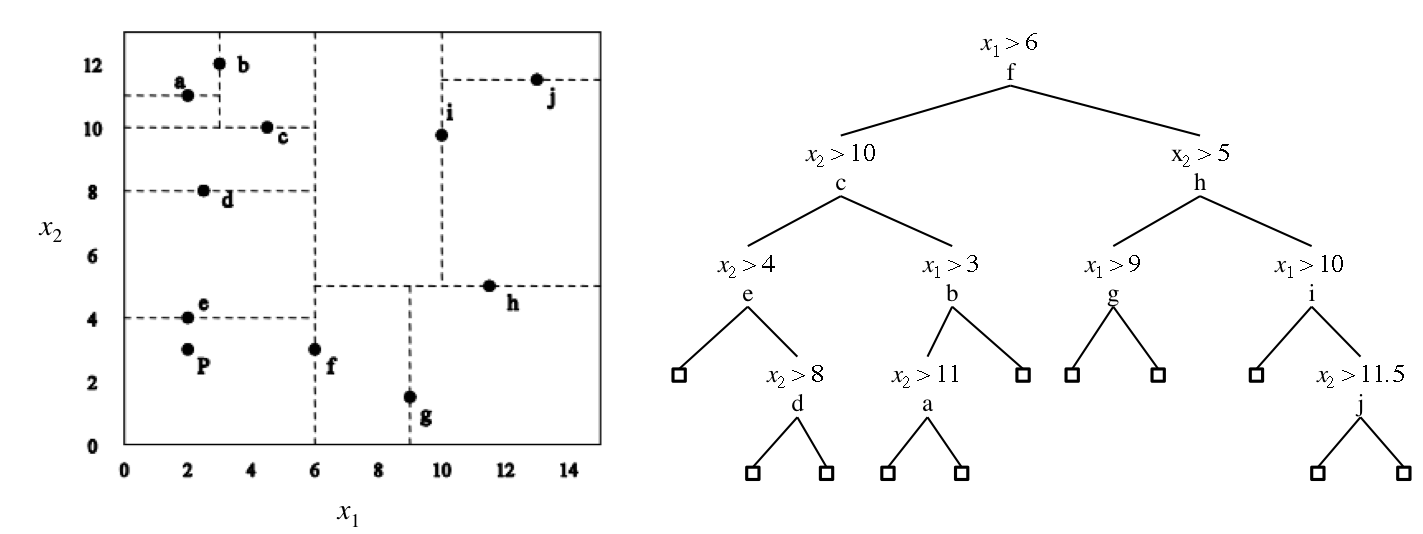
| Instance | x | y |
|---|---|---|
| a | 2 | 11 |
| b | 3 | 12 |
| c | 5 | 10 |
| d | 2 | 8 |
| e | 2 | 4 |
| f | 6 | 3 |
| g | 9 | 2 |
| h | 12 | 5 |
| i | 10 | 10 |
| j | 13 | 11.5 |
<Wisc username>_hw2.zip.
Upload this zip file as Homework #2 at the course Canvas site.